Nomen: What's in a Name
- How can we label or name topics that automatically extracted from a software project's version control commit log comments?
- Given a software specific LDA extracted topic, can we label it with non-functional requirements automatically, without training?
- Given a software specific LDA extracted topic, can we label it with non-functional requirements semi-automatically?
Automated topic naming to support cross-project analysis of software maintenance activities
Accepted to MSR 2011
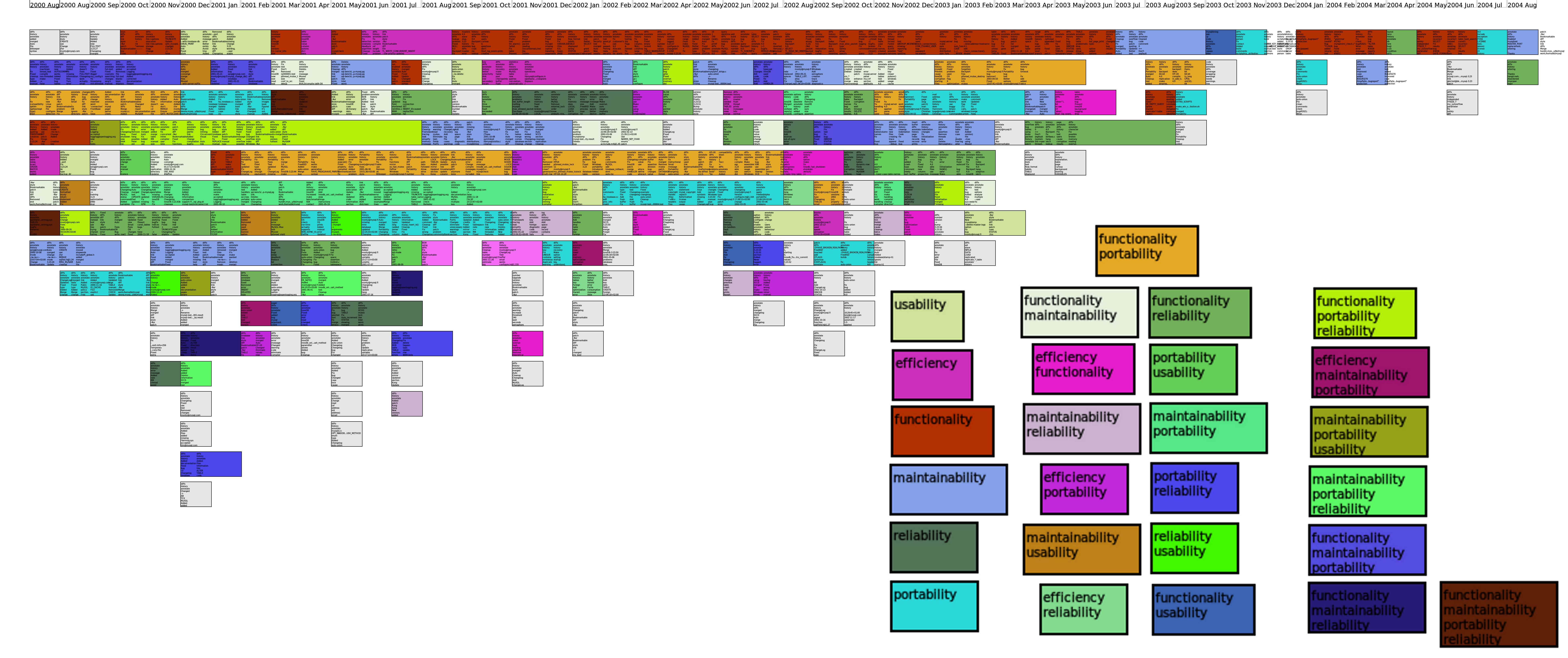
Researchers have employed a variety of techniques to ex- tract underlying topics that relate to software development artifacts. Typically, these techniques use semi-unsupervised machine-learning algorithms to suggest candidate word-lists. However, word-lists are difficult to interpret in the absence of meaningful summary labels. Current topic modeling tech- niques assume manual labelling and do not use domain- specific knowledge to improve, contextualize, or describe re- sults for the developers. We propose a solution: automated labelled topic extraction. Topics are extracted using Latent Dirichlet Allocation (LDA) from commit-log comments re- covered from source control systems such as CVS and Bit- Keeper. These topics are given labels from a generalizable cross-project taxonomy, consisting of non-functional require- ments. Our approach was evaluated with experiments and case studies on two large-scale RDBMS projects: MySQL? and MaxDB?. The case studies show that labelled topic ex- traction can produce appropriate, context-sensitive labels relevant to these projects, which provides fresh insight into their evolving software development activities.
- The paper: http://softwareprocess.es/z/msr2011.pdf
- Slides: http://softwareprocess.es/z/msr2011-ahindle-nernst-presentation.pdf (8mb)
- Video presentation:
Observations:
- WordNET? is not enough.
- Domain specific knowledge improves performance.
Paper: Automated topic naming to support analysis of software maintenance activities [unpublished]
Researchers have used topic modeling and concept location to understand the latent topics of software development artifacts. These techniques use unsupervised machine-learning algorithms to recover topics. These topics are word-lists and are difficult to distinguish and interpret. Topics are not meaningful until they have been named or interpreted. Current topic labelling approaches are manual, and do not use domain-specific knowledge to improve, contextualize, or describe results for the developers. We propose a solution: labelled topic extraction. Topics are extracted using Latent Dirichlet Allocation (LDA) from commit-log comments recovered from source control systems such as CVS and Bit-Keeper. These topics are given labels relating to a generalizable cross-project taxonomy consisting of non-functional requirements. Our approach was evaluated with experiments and case studies on two large-scale RDBMS projects: MySQl? and MaxDB?. Labelled topic extraction produces appropriate, context-sensitive labels relevant to these projects, which provides fresh insight into their evolving software development activities.
Paper2: What's in a Name [unpublished]
Abstract
Within the field of mining software repositories, many approaches, such as topic modeling and concept location, rely on the automated application of machine learning algorithms to corpora. Unfortunately the output of these tools is often difficult to distinguish and interpret as they are often so abstract. Thus to have a meaningful discussion about the topics of software development, we must be able to devise appropriate labels for extracted topics. However, these approaches neither use domain-specific knowledge to improve results, nor contextualize those results for developers. While too much specificity can produce non-generalizable results, too little produces broad learners that do not provide much immediately useful detail. This paper implements `labelled topic extraction', in which topics are extracted from commit comments and given labels relating to a cross-project taxonomy. We focus on non-functional requirements related to software quality as a potential generalization, since there is some shared belief that these qualities apply broadly across many software systems and their development artifacts. We evaluated our approach with an experimental study on two large-scale database projects, MySQL? and MaxDB?. We extracted topics using Latent Dirichlet Allocation (LDA) from the commit log comments of their version control systems (CVS and BitKeeper?). Our results were generalizable across the two projects, showing that non-functional requirements were commonly discussed, and we identified topic trends over time. Our labelled topic extraction technique allowed us to devise appropriate, context-sensitive labels across these two projects, providing insight into software development activities.
- The paper
- Page 8 enlarged:
- Mirror the paper, the source code and the data:
- Annotated LDA Topics from MySQL and MaxDB
- The latest paper
- Revision Data for Maxdb76 2.6mb
- Revision Data for Maxdb7500 (1.2 mb)
- MaxDB original CVS repo 1 Gigabyte!
- LDA-Image This is a virtualbox image of the LDA running rig for the What's in a name paper. It is pretty big and you can run the software.
- If software is unlabelled license wise, assume a GPLv3 license.
- Wordlists used in this study. Please cite us if you use these lists. Citing either of the papers on this page would be fine! Thank you! Some of these wordlists were derived from WORDNET.
{kind=link}
{kind=link}